Illumina Complete Long Read 기술

Illumina Complete Long Read 시퀀싱 기술 소개
이 신기술은 유전체의 가장 어두운 구석까지 더 밝게 비춰 줄 것입니다. Illumina Complete Long Read는 유전체의 가장 까다로운 영역을 해결하는 데 도움이 되며 단일 플랫폼에서 쇼트 리드(short read)와 롱 리드(long read)를 가능하게 하여 롱 리드 시퀀싱에 접근하고 이를 간소화합니다.
Illumina Complete Long Read 기술은 표준 차세대 시퀀싱(next-generation sequencing, NGS) 워크플로우와 신뢰할 수 있는 Illumina sequencing by synthesis(SBS) chemistry를 사용하여 새로운 고성능 assay로 구성된 포트폴리오를 지원합니다.
제품:
- Illumina Complete Long Read Prep, Human: Illumina에서 가장 정확하고 가장 포괄적인 인간 전장 유전체 assay입니다. 인간 유전체 전체에 걸쳐 매우 정확한 쇼트 리드 및 롱 리드의 강도를 활용하여 구현됩니다.
- Illumina Complete Long Read Prep with Enrichment, Human: 가장 큰 가치를 제공하는 표적 롱 리드로 매핑하기 어려운 것으로 알려져 있는 영역의 커버리지(coverage)를 향상시키기 위한 유연하고 비용 효율적인 솔루션입니다. Illumina DesignStudio 소프트웨어로 구현되는 사전 설계 및 맞춤형 패널과 호환됩니다.
- Illumina Complete Long Read Prep with Enrichment and Human Comprehensive Panel: Illumina Complete Long Read Prep with Enrichment를 사용하여 단백질 코딩(coding) 유전자 내에 있는 매핑하기 어려운 영역의 커버리지를 향상시키기 위해 사전 설계 및 최적화된 패널입니다.
주요 기능
접근 가능성 및 비용 효율성
기존 Illumina 시퀀싱 시스템의 롱 리드 및 쇼트 리드를 둘 다 사용합니다. 특수 장비 없이도 표준 NGS 업무 흐름에 손쉽게 통합할 수 있습니다. 포괄적이며 간단한 버튼 조작만으로 수행 가능한 클라우드 분석 기능을 BaseSpace Sequence Hub 또는 Illumina Connected Analytics에서 사용할 수 있습니다.
견고성 및 유연성
낮은(50 ng) DNA 사용량으로 오염물과 동결/해동 사이클에 잘 견딥니다. DNA 사용량이 최저 10 ng인 5~7 kb의 N50으로 연속 롱 리드 시퀀스를 생성합니다. 소형 표적 패널부터 최대 롱 리드 전장 유전체까지 확장할 수 있는 매우 유연한 롱 리드입니다.
확장성 및 간소화된 워크플로우
특수 장비 없이도 단순하고 간소화되었으며 자동화를 지원하는 라이브러리 준비가 가능합니다. NovaSeq X 시리즈를 사용하여 연간 최대 3,000개의 롱 리드 전장 유전체 또는 수만 개의 표적 롱 리드 패널을 분석할 수 있습니다. 처리량이 더 적은 소모품을 사용하여 더 적은 샘플 수의 표적 롱 리드를 분석함으로써 일괄 처리 요건을 줄입니다.
고도의 정확성
BaseSpace Sequence Hub 또는 Connected Analytics에서 입증된 Illumina SBS 및 DRAGEN 분석을 기반으로 합니다. PrecisionFDA Truth Challenge v21로 측정 시 인간 전장 유전체의 경우 99.90%의 F1 점수(단일 염기서열 변이 + 삽입/결실) 기능이 있으며 > 100 kb인 영역의 페이징된 시퀀싱을 지원합니다.
Illumina Complete Long Read 기술의 원리
태그멘테이션은 긴 절편 크기를 절편화 및 표준화하는 데 사용됩니다. 긴 절편은 단일 분자의 롱 리드 정보를 포착하고 증폭하기 위해 ‘land-marked’ 패턴으로 표시되고 증폭됩니다. 랜드마크 표시가 된 절편은 인리치먼트되거나 시퀀싱을 위한 표준 라이브러리로의 태그멘테이션으로 직접 이동할 수 있습니다. 표시 및 비표시 데이터가 결합되어 매우 정확성이 높은 완벽한 롱 리드를 생성합니다.
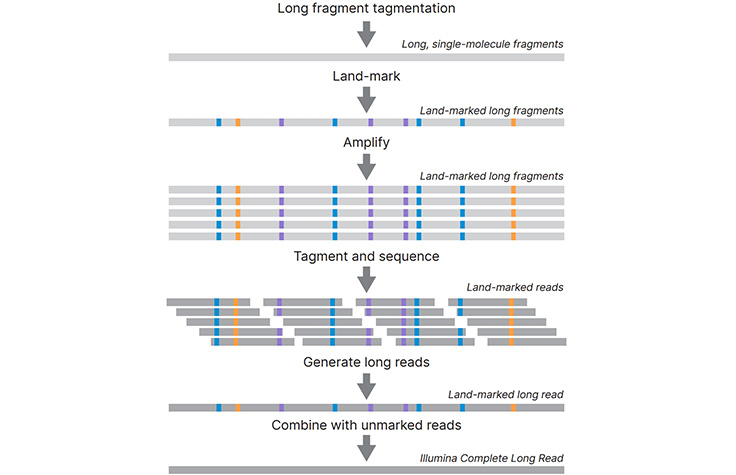
Illumina Complete Long Read Prep, Human 전장 유전체 시퀀싱 워크플로우
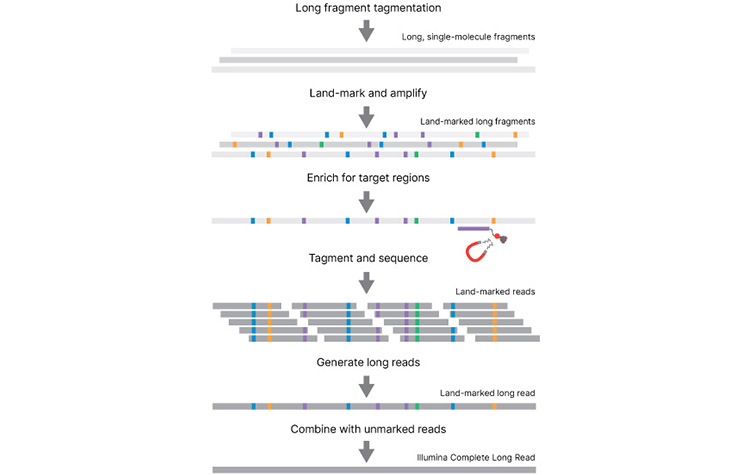
Illumina Complete Long Read Prep with Enrichment, Human 전장 유전체 시퀀싱 워크플로우
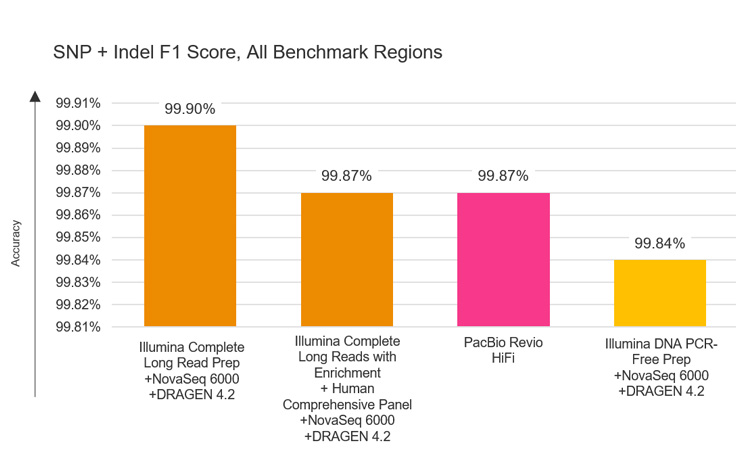
Illumina Complete Long Read 및 PrecisionFDA Truth Challenge v2 데이터 세트
인간 전장 유전체 시퀀싱
Illumina Complete Long Read는 PrecisionFDA Truth Challenge v2 데이터 세트1로 변이 검출(variant calling)에 대해 전례 없는 정확성을 제공하며, 이는 F1 점수(%), 즉 진양성 및 진음성 결과를 총 결과의 비율로 계산하여 측정한 것입니다.
- 탁월하며 수상 경력에 빛나는 Illumina SBS + DRAGEN 분석1-3의 정확성을 기반으로 개선
- 기존 WGS 데이터 세트를 강화하거나, 더 큰 변이 발견을 촉진하는 도구로서, 그리고 유전체의 까다로운 영역을 해결하는 데 사용 가능
- 품질이 가변적인 샘플 전체에 걸쳐 매우 정확하고 신뢰할 수 있는 결과 제공
- 알려져 있는 까다로운 영역에서 표적 롱 리드를 통해 롱 리드 WGS와 비견할 만한 비용 효율적인 정확성 지원
Illumina Complete Long Read 제품
Illumina Complete Long Read Prep, Human
Illumina Complete Long Read를 기반으로 한 최초의 제품인 Illumina Complete Long Read Prep, Human은 롱 리드 인간 전장 유전체 시퀀싱(WGS)용으로 설계되었습니다.
- 특수 장비가 없는 단순한 1일 라이브러리 준비 워크플로우
- 공동 유전된 대립유전자, 일배체형(haplotype) 정보 및 위상 de novo 돌연변이를 식별하기 위해 페이징된 시퀀싱 수행
- NovaSeq X 시리즈로 연간 최대 3000개의 롱 리드 전장 유전체까지 런당 샘플 수 4개 분석
- 분석에는 ≥ 30× WGS 필요, PCR-free 권장
Illumina Complete Long Read Prep with Enrichment, Human
Illumina Complete Long Reads with Enrichment는 상호보완하는 표적 롱 리드를 사용한 인간 유전체 시퀀싱을 위해 설계되었습니다.
- 특수 장비가 필요 없는 자동화 지원 2일 라이브러리 준비 워크플로우
- 분석에는 ≥ 30× 쇼트 리드 전장 유전체 필요, PCR-free 권장. 기존 데이터 세트와 호환
- NovaSeq X 시리즈에서 Human Comprehensive Panel로 10B 플로우 셀당 24개의 샘플 분석
- 사전 설계된 맞춤형 패널로 비용 효율적인 롱 리드 인간 유전체 데이터에 대해 추가적인 유연성과 확장성 창출:
- Human Comprehensive Panel
- 다수의 사전 설계된 패널
- DesignStudio 소프트웨어를 사용하는 맞춤형 패널
- 제3자 패널 호환성
Illumina Complete Long Read 기술
주요 워크플로우
추출
특수 프로토콜, 절단, 크기 선택 필요 없이 혈액 또는 타액에서 DNA 추출
준비
표준 장비를 사용하여 권장되는 50 ng 또는 최저 10 ng 사용량 DNA로 자동화를 지원하는 워크플로우를 이용하여 라이브러리 준비
시퀀스
분석
DRAGEN Illumina Complete Long Read 앱을 BaseSpace™ Sequence Hub에서 사용
Interested in the power of Illumina Complete Long Reads for your lab?
Illumina의 워크플로우와 분석이 롱 리드 기술의 정확성과 확장성으로부터 어떤 이점을 누릴 수 있는지에 관해 전문가와 상담해 보세요. 지금 바로 양식을 작성하여 주문 견적을 요청해 보세요.근거 데이터
Illumina Complete Long Read 데이터를 통해 기존에 까다로웠던 영역, 매우 다형성이 높은 영역, 위유전자 및 동종간 상동체, 크기가 큰 삽입(insertion)-결실(deletion) 변이 및 구조적 변이에서 정렬 및 변이 검출(variant calling)을 개선할 수 있습니다.
Illumina Complete Long Read Prep, Human 데이터 시트 다운로드
Illumina Complete Long Read Prep with Enrichment, Human 데이터 시트 다운로드
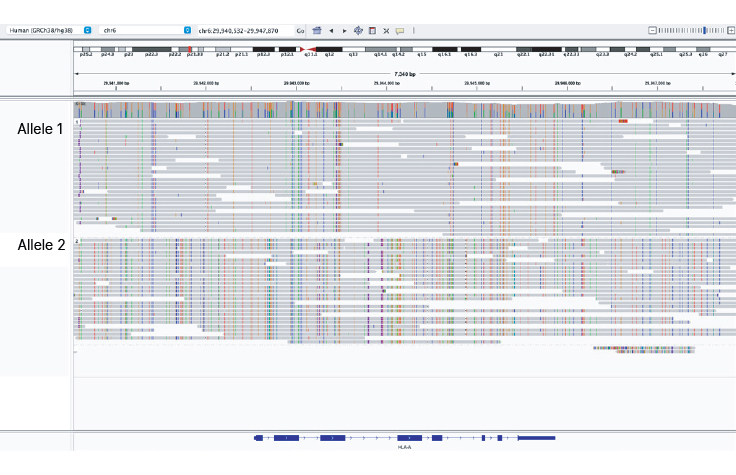
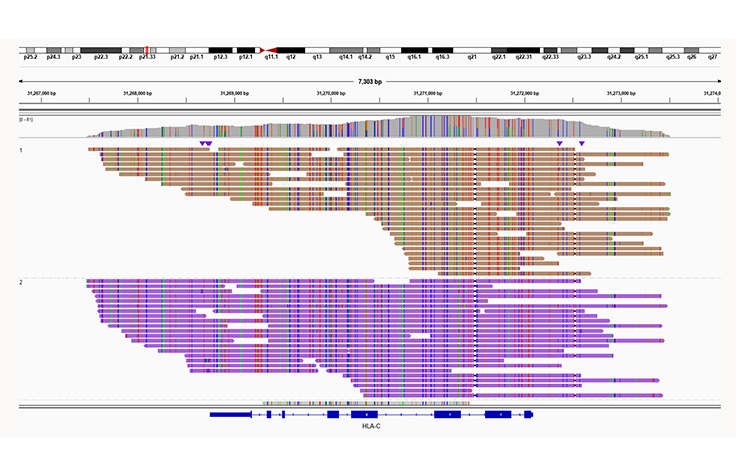
명확한 일배체형 할당
Illumina Complete Long Read는 HLA-A 유전자와 같은 매우 다형성이 높은 영역을 해결할 수 있습니다. HLA 영역의 균일한 커버리지는 HLA 대립유전자의 정확한 페이징을 가능하게 합니다.

크기가 큰 결실 검출
SEMG1 유전자의 이형 180 bp 결실은 Illumina Complete Long Read 및 시판 중인 롱 리드 두 가지 모두를 통해 명확히 검출됩니다.
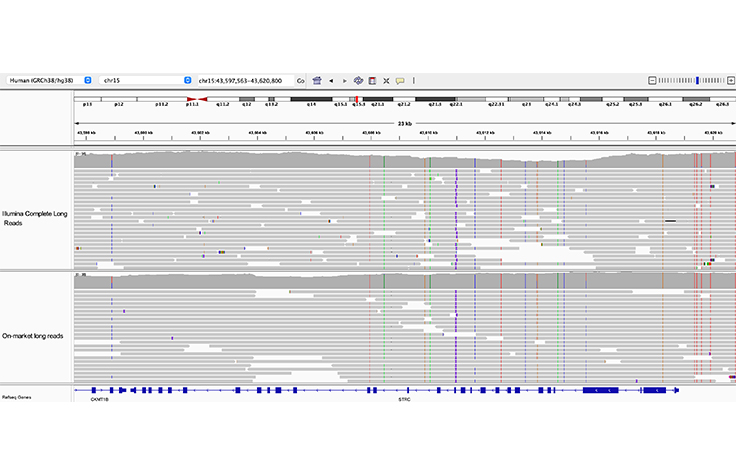
위유전자로부터의 STRC 해상도
Illumina Complete Long Read와 시판 중인 롱 리드 모두 23 kb STRC 유전자를 위유전자인 pSTRC로부터 명확히 분석해 냅니다.

단백질 코딩 유전자의 까다로운 영역에서 강화된 커버리지
RHCE 유전자의 커버리지가 낮은 영역은 Illumina Complete Long Read Prep with Enrichment 및 Human Comprehensive Panel을 사용하여 해결됩니다.
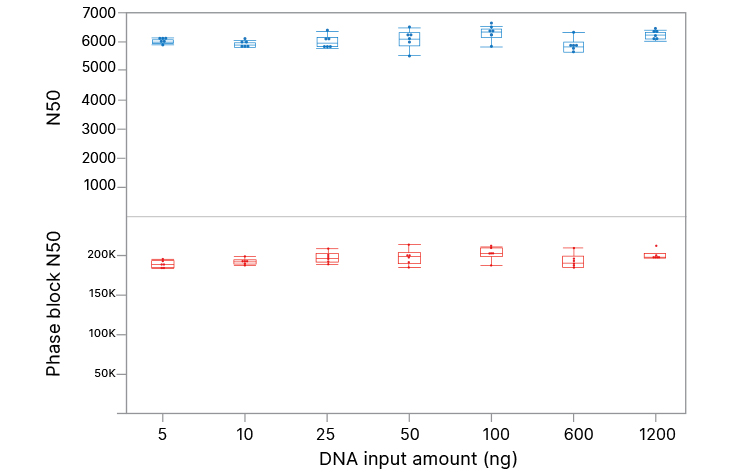
매우 다양한 DNA 사용량에 걸친 고품질 성능
DNA 사용량이 5 ng에서 1,200ng까지인 Illumina Complete Long Read Prep, Human은(3회 반복 실험 시) N50 및 위상 블록 N50에 대해 비슷한 데이터 품질을 생성합니다. N50은 총 어셈블리 길이의 50%에서 가장 짧은 콘티그(또는 위상 블록)의 시퀀스 길이입니다.
인간 페이징
Illumina Complete Long Read로 공동 유전된 대립유전자, 일배체형(haplotype) 정보 및 위상 de novo 돌연변이를 식별하기 위해 페이징된 시퀀싱 수행.
신뢰할 수 있는 Illumina 시퀀싱 시스템과 호환
Illumina Complete Long Read 기술은 NovaSeq X Plus, NovaSeq X 및 NovaSeq 6000 Sequencing System과 호환되어 동일한 기기에서 롱 리드 및 쇼트 리드 데이터 모두에 액세스할 수 있습니다.

리소스
Illumina Complete Long Read 웨비나
이 프레젠테이션에서는 Complete Long Read의 사용 사례를 공유하고 전 세계의 협업자들이 진행하고 있는 연구를 소개합니다.
Illumina Long Read 기술의 이점
Illumina의 ASHG 2022 CoLab 회담에서 녹화한 프레젠테이션에서는 Illumina의 새로운 롱 리드 기술의 이점 및 로드맵의 다른 기술적 혁신이 이를 보완하는 방식에 대해 설명합니다.
Illumina Long Read 기술 성능 데이터 비교
Illumina Complete Long Read 기술은 연구자들이 매핑하기 가장 까다로운 유전체의 가장자리까지 처리할 수 있도록 지원합니다.
인간 WGS용 Illumina Complete Long Read 소프트웨어 분석 워크플로우
Illumina Complete Long Read 인간 유전체 분석 이면의 근본적인 원칙을 깊이 파고드는 심도 있는 기사입니다.
Illumina Complete Long Read Prep with Enrichment, Human을 위한 맞춤형 패널 설계
Illumina Complete Long Read Prep with Enrichment, Human이 입증된 Illumina 쇼트 리드 WGS를 보완하는 방식을 요약하고 가장 큰 가치를 제공하는 부분에 롱 리드 시퀀싱의 초점을 맞추는 Technical Note입니다.
참고 문헌
- PrecisionFDA. Truth Challenge V2: Calling Variants from Short and Long Reads in Difficult-to-Map Regions. precision.fda.gov/challenges/10
- Mehio R, Ruehle M, Catreux S, et al. DRAGEN Wins at PrecisionFDA Truth Challenge V2 Showcase Accuracy Gains from Alt-aware Mapping and Graph Reference Genomes. illumina.com/science/genomics-research/articles/dragen-wins-precisionfda-challenge-accuracy-gains.html
- Illumina. Accuracy improvements in germline small variant calling with the DRAGEN Bio-IT Platform. illumina.com/content/dam/illumina/gcs/assembled-assets/marketing-literature/dragen-v4-accuracy-app-note-m-gl-01016/dragen-v4-accuracy-app-note-m-gl-01016-kor.pdf